DecaWave’s DW1000
DW1000 is a UWB communication and ranging module manufactured by DecaWave.
It provides a fairly good ranging accuracy (< 2 cm). Not only a simple anchor-tag ranging system, let’s make a practical centimeter-level precision indoor positioning system using it
System Design
Overview
A setup is shown in a figure below:
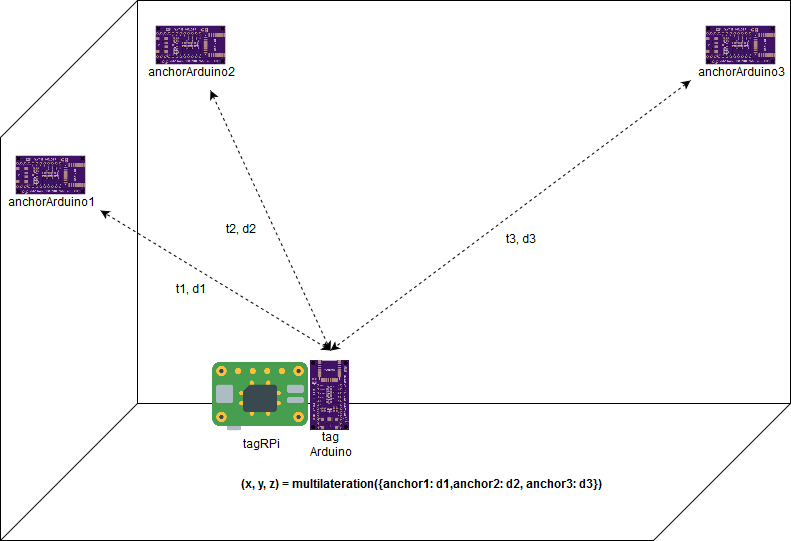
- A tag
- A tag is composed of two components—Raspberry Pi and Arduino Pro Mini
- Raspberry Pi controles a higher level indoor positioning system
- It triggers Arduino Pro Mini to probe anchors and measure distance between it and each anchor
- It requests distance measurements on Arduino Pro Mini and locate itself through trilateration
- Arduino Pro Mini
- It is required due to similar reasons of anchors
- It receives commands from Raspberry Pi and executes the corresponding process
Processes are:
- Probing anchors nearby and exchanging series of frames with each anchor
to measure distance
- Reporting probed anchors and measured distance values
- Anchors
- They are deployed in a site of interest and their 2D/3D coordinates are known
- They are implemented on Arduino Pro Mini for the following reasons:
- Arduino Pro Mini’s low power consumption
- Anchor’s fast response requirement (order of milliseconds)
- Anchor’s simple tasks (receiving and transmitting UWB frames)
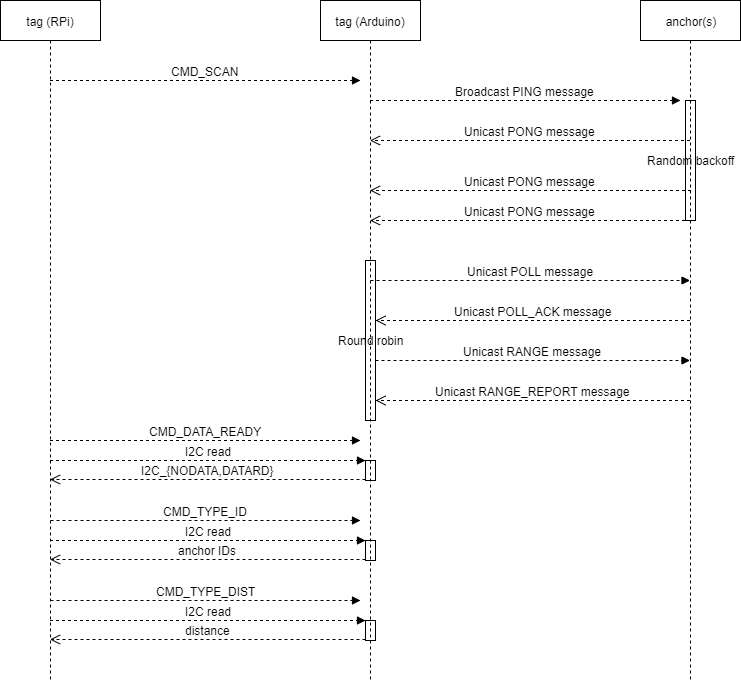
An overall sequence diagram is illustrated below. Tag (Arduino) is actually composed of Arduino Pro Mini and DW1000.
State Machine: Tag
A figure below is a state diagram of a tag:
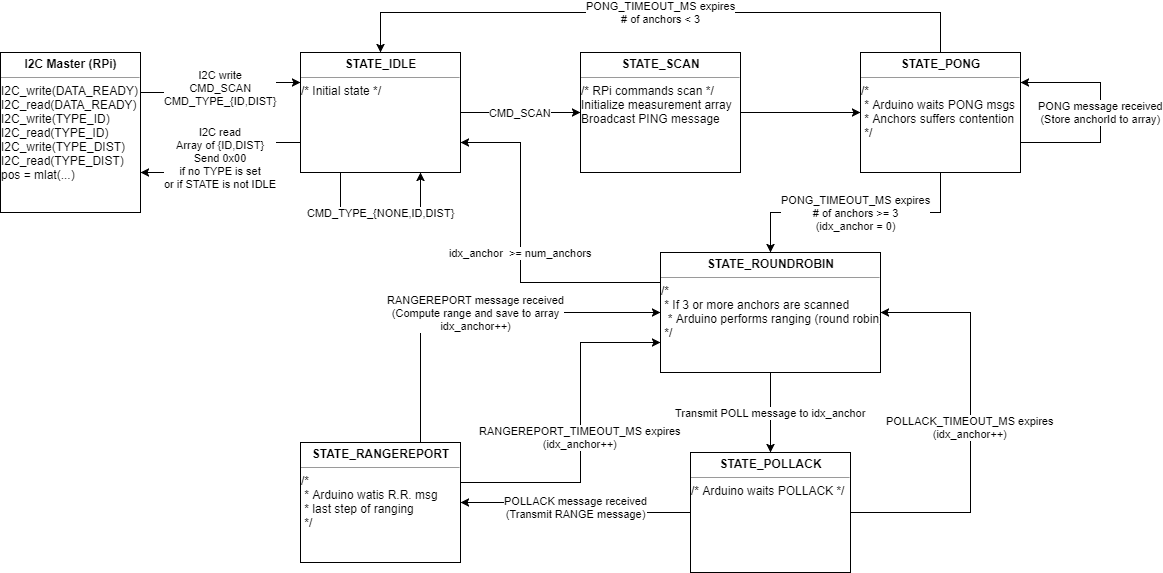
When a Raspberry Pi commands via I2C to scan, it goes into SCAN state and broadcasts a PING message. Going into PONG state immediately, it waits for PONG messages from anchors nearby for a certain duration. I set it to 100 ms.
If it discovers 3 or more anchors during the PONG state, it goes into ROUNDROBIN state. It exchanges 4 messages with each discovered anchor sequentially, i.e. POLL to an anchor, POLL_ACK from an anchor, RANGE to an anchor, and RANGE_REPORT from an anchor. After sending POLL and RANGE message, it waits for a response message for a certain timeout of 10 ms.
After 4 messages are exchanged with each anchor, it calculates distance between an anchor using Tx/Rx timestamp. It adopts two-way ranging algorithm, which is a bit computational intensive, but I think it is not that much intensive. For more information about two-way ranging, please refer the official appliclation note APS013 by DecaWave.
State Machine: Anchor
A state diagram of an anchor is simple:
- It normally stays at
IDLE state
- If it receives a
PING message, it tries to send a PONG message with a random delay between 0 and 90 ms to avoid the collision and goes into PENDING_PONG state
- If it receives a
POLL message and sends a POLL_ACK message, it goes into RANGE state and waits for a RANGE message is received
- If timeout of 10 ms expires, it returns to
IDLE state
- If it receives a
RANGE message, it sends a RANGE_REPORT message to a tag
Implementation
The whole implementation can be found in my GitHub repository. I used arduino-dw1000 for controlling DW1000 using Arduino. I followed wiring between Arduino Pro Mini and DW1000 as defined in examples/Ranging{Anchor,Tag} of the library. Only I2C interface is needed to connect Raspberry Pi and Arduino Pro Mini